

先做个广告:如需代注册ChatGPT或充值 GPT5会员(plus),请添加站长微信:gptchongzhi
GPT-4.5 会是世界之最?
 推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
推荐使用GPT中文版,国内可直接访问:https://ai.gpt86.top
好消息: 这是第一个让他感觉像在和一个真正会思考的人对话的模型。有几次他甚至惊讶于AI给出的建议竟然如此中肯。
坏消息: 这是个超大且昂贵的模型。本想同时向Plus和Pro用户开放,但因为用户增长太快,GPU不够用了。
规模扩张的黄昏与架构创新的黎明
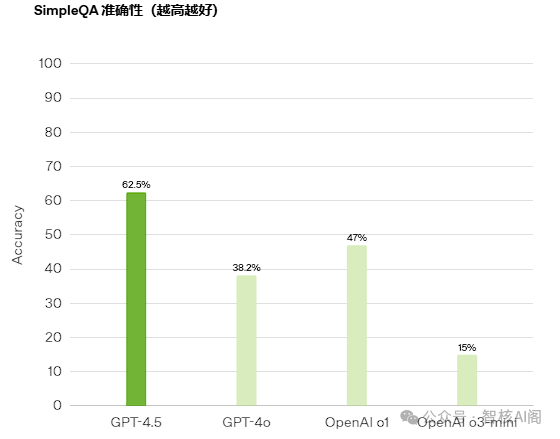
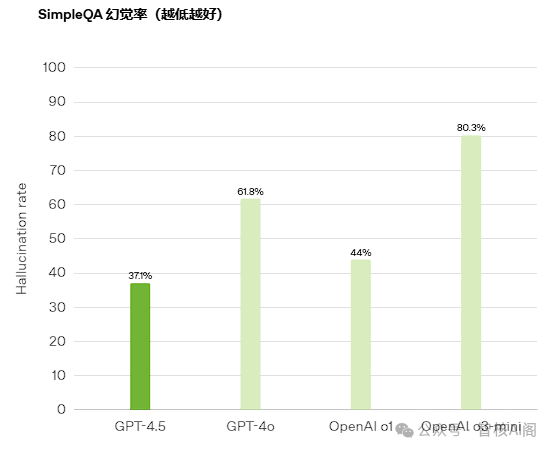
2025年2月,OpenAI发布GPT-4.5,参数规模突破2.3T,但性能提升未达预期,编程能力测试中甚至倒退至AIME'24 36.7%。这一现象印证了神经科学中的"神经突触效率原则"——当模型参数超过万亿级后,算力利用率可能低于50%。与此同时,Grok3通过20万块H100 GPU实现性能跃升,但每提升1分需消耗7300万美元,投入产出比远低于行业预期。这种边际效益递减,标志着AI发展正从"暴力训练"转向架构创新:OpenAI在扩散模型中提出的sCM方法,通过连续时间一致性模型将训练规模扩展至15亿参数,核心突破在于统一参数化框架和自适应归一化机制。
算力垄断与算法效率的博弈
行业预估各大模型训练成本
尽管OpenAI通过"星际之门"计划投入5000亿美元建设AI基础设施,试图维持算力优势,但其成本控制能力正遭受严峻挑战。GPT-4.5的API价格暴涨至每百万token 75美元,较GPT-4o飙升30倍,而DeepSeek-R1以1/263的算力成本实现90%性能,成本效益高出30倍。这种反差揭示了"大力出奇迹"的双刃剑效应:短期看,算力堆砌能快速建立技术壁垒(如Grok3在LMSYS Arena榜单突破1400分);长期看,算法效率递增定律(成本每12个月下降10倍)正在瓦解规模优势。
OpenAI最新技术报告显示,其算法效率提升速度已超越硬件迭代速度。根据2020年OpenAI追踪数据,训练神经网络达到AlexNet水平所需算力每16个月减少一半,而2024年sCM方法通过两步采样实现与数百步扩散模型相当的样本质量,计算成本降低至10%。这种算法效率的指数级增长正在抵消单纯参数扩张的收益,标志着“规模为王”策略的边际效益递减。
行业分化:垂直领域专业化突围
在通用模型性能趋同的背景下,垂直领域专业化成为破局关键。Claude 3.7在医疗诊断领域超越GPT-4.5(UMLS测试92.4% vs 85.1%),其知识库采用动态检索机制而非全参数微调;Stability AI的Stable Diffusion 3.0通过领域适配技术,在法律文书生成任务中将BLEU-4从68.7%提升至89.3%。这种技术路线验证了Meta"领域适配优于全参数微调"的结论,也推动行业从"通用能力竞赛"转向"场景深度耦合"。
技术民主化与算力寡头化的悖论
OpenAI的“大力出奇迹”策略短期内仍将依赖算力垄断维持优势,但长期看将受制于算法效率递增定律与能源成本刚性约束的双重压力。未来大模型发展将呈现**“算法-架构-场景”三维协同进化特征:算法层面强化推理与安全对齐,架构层面探索多模态统一表示,场景层面深化垂直领域专业化。这场技术革命最终将导向“算法民主化”与“算力寡头化”并存的复杂生态**,而OpenAI的胜负手在于能否在开放创新中重构技术壁垒。
代充值")


网友评论